Active Semantic Mapping for Household Robots:
Rapid Indoor Adaptation and Reduced User Burden
Abstract
Active semantic mapping is essential for service robots to quickly capture both the environment’s map and its spatial meaning, while also minimizing users’ burdens during robot operation and data collection. SpCoSLAM, which is a semantic mapping with place categorization and simultaneous localization and mapping (SLAM), offers the advantage of not being limited to predefined labels, making it well-suited for environmental adaptation. However, SpCoSLAM presents two issues that increase users’ burdens: 1) users struggle to efficiently determine a destination for the robot’s quick adaptation, and 2) providing instructions to the robot becomes repetitive and cumbersome. To address these challenges, we propose Active-SpCoSLAM, which enables the robot to actively explore uncharted areas while employing CLIP as image captioning to provide a flexible vocabulary that replaces human instructions. The robot determines its actions by calculating information gain integrated from both semantics and SLAM uncertainties.
Action Determination
The robot navigates to the position with the maximum information gain among the candidate points. The IG in Active-SpCoSLAM consists of a weighted sum of three IGs: related to spatial concepts, self-location, and maps, respectively.
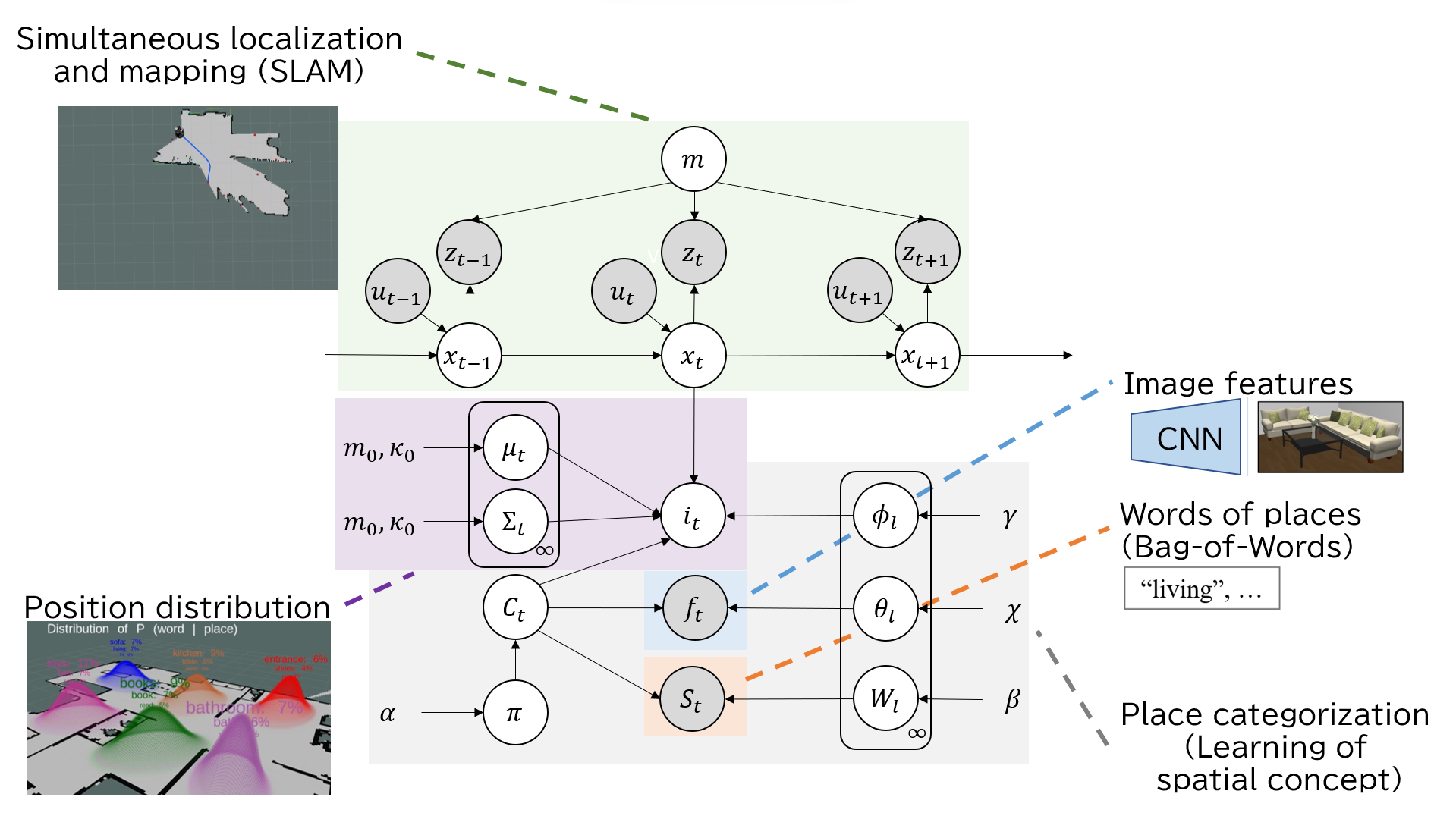
Learning Spatial Concept
First, the robot acquires multiple images of its surroundings with the head camera. Then, the images are input to ClipCap for caption generation, and the images are input to CNN to obtain image features. The robot learns location concepts by categorizing these, plus self-position, into three multimodal pieces of information.
Citation
@inproceedings{ishikawa2023active,
title={Active semantic mapping for household robots: rapid indoor adaptation and reduced user burden},
author={Ishikawa, Tomochika and Taniguchi, Akira and Hagiwara, Yoshinobu and Taniguchi, Tadahiro},
booktitle={2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC)},
pages={3116--3123},
year={2023},
organization={IEEE}
}
Other Links
Acknowledgements
This work was supported by the Japan Science and Technology Agency (JST), Moonshot Research & Development Program (Grant Number JPMJMS2011), and the Japan Society for the Promotion of Science (JSPS), KAKENHI Grant Number JP20K19900, JP23K16975 and JP22K12212.